
Join us on Facebook!
Join us on Facebook!
— Written by Triangles on June 07, 2021 • updated on September 04, 2021 • ID 90 —
From routing to IP addressing, a look at the protocol that gives life to the Internet.
Introduction to computer networks — A bird's-eye view on the art of resource sharing from one computer to another.
Understanding the Internet — “Is that thing still around?” — Homer Simpson
Introduction to the TCP/IP protocol — The official rules that allow computers to communicate over the Internet.
Introduction to TCP: Transmission Control Protocol — One of the most important, high-level protocols in the Internet Protocol Suite.
Network programming for beginners: introduction to sockets — A theoretical look at one of the most popular programming tools for exchanging data over computer networks.
Making HTTP requests with sockets in Python — A practical introduction to network programming, from socket configuration to network buffers and HTTP connection modes.
Welcome to the 4th episode of the Networking 101 series! In the previous article, Introduction to the TCP/IP protocol, I explored the set of rules known as the TCP/IP protocol that brings the Internet to life.
The TCP/IP protocol is a collection of protocols that determines how the Internet should work. The TCP/IP name comes from two of the most important protocols it contains: the Transmission Control Protocol (TCP) and the Internet Protocol (IP). In this article I want to investigate the latter.
The Internet Protocol is a set of rules that determine how data should travel across computers over a network and reach the correct destination. You can find the original document here published by the Internet Engineering Task Force (IETF), along with additional corrections and fixes (here, here and here). It is a low-level protocol, as it belongs to the Network layer in the TCP/IP protocol stack:
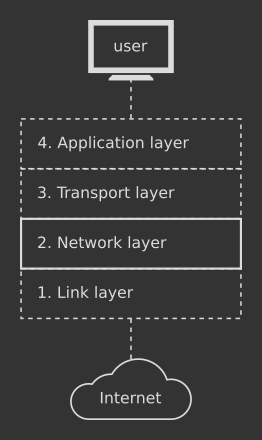
The Internet Protocol introduces two important networking concepts:
The two concepts above go hand in hand: let's take a deeper look.
Routing is the ability of a computer network to dispatch messages around, say from computer A to computer B. As seen in chapter #2 of this series, the Internet is a huge entity made by billions of computers connected together through cables: the Internet Protocol defines how a message should travel across those computers to reach its destination.
More precisely, the Internet is a global network made of several smaller networks, which in turn contain hosts. Routers are special computers located on the edges of those networks, acting like gatekeepers for packages that enter or exit. Routers do the hard work of picking up the message you want to send and move it in the right direction. The message is passed from one router to another until the destination (i.e. the host) is reached.
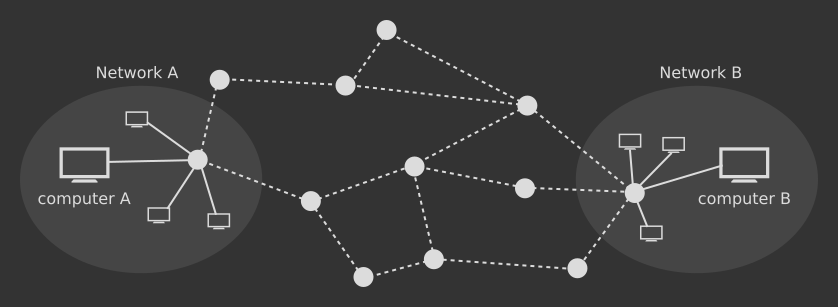
The physical path between computer A and computer B is filled with routers. A package that needs to traverse one or more networks will inevitably pass through all the networks' routers and get redirected by them, until the target host is reached. The Internet Protocol describes how routers should do such redirection job as efficiently as possible.
In the picture above you can notice there is more than one way for a message to reach the destination. Routers are able to choose the shortest path, and also adjust it if the network is overloaded — in case many other computers are trying to exchange data at the same time — or if there is a network malfunction somewhere along the way.
Part of this magic is performed through routing tables, special databases stored into routers. Routing tables define the path a message should take to reach every destination that the router is responsible for. When a router receives a message, it parses it to understand its intended destination, then it determines where to route the message based on the information located in its routing tables.
In the third chapter of this series I mentioned how the TCP/IP protocol stack wants the data to be split into chunks: the Internet Protocols calls those chunks datagrams, or also Internet Protocol packets. Datagrams are generated by programs from upper layers in the TCP/IP protocol stack that make use of the Internet Protocol.
A datagram is made of two parts:
I previously said that routers dispatch messages. They actually deal with datagrams: when a datagram arrives, the router parses the datagram header in order to understand where to route it. It then matches the destination address to its routing table and act accordingly: if the recipient belongs to its network, the router passes the datagram to that specific host, otherwise the datagram is forwarded to a different router in another network.
I will investigate all the fields a datagram header consists of in future chapters of this series, when I will get my hands dirty with network programming. For now it is interesting to note the presence of the Time-to-live (TTL) field (renamed Hop limit more recently) that determines how long a datagram should float around the Internet before being destroyed. When the datagram arrives at a router, the router decrements the TTL field by one unit. When the TTL field hits zero, the router discards the datagram. This is useful to prevent datagrams from going in circles forever on the Internet.
Different networks allow different datagram lengths, in bytes: some want short datagrams, some others allow the maximum size available (65,535 bytes). A fat datagram needs to be split up into smaller ones when it traverses a network that doesn't understand big datagrams. Such mechanism is called fragmentation and is supported by the Internet Protocol. A bunch of fields in the datagram header keep track of the number of sub-datagram a datagram has been split into and are used by the receiver to later reassemble the information.
Sending data in Internet Protocol is conceptually simple: generate a datagram, then pass it to a router that will address it where needed. Rinse and repeat for every datagram your message is made of. Also, no connection needs to be established in advance in order to talk to a router: just send it the datagram and you're done. For this reason the Internet Protocol is a form of connectionless communication.
In connectionless communication datagrams are sent without first ensuring that the recipient is available and ready to receive them: datagrams might arrive in a different order than expected. Or might not arrive at all, in case there are misconfigured or malfunctioning routers along the way. For this reason the Internet Protocol is almost never used directly, rather as a foundation for other protocols — for example the TCP + IP combo — where fancier connections are required. I will explore the improvements of the TCP protocol in the next chapter of this series.
The IP address is the second key concept introduced by the Internet Protocol. An IP address is a 32-bit number where each 8-bit segment is separated by a dot (.). Those segments are called octets. For example: 000100001.01100000.10111011.00000010. Since binary is difficult to read, IP addresses are often represented in the dot-decimal notation, where each octet is expressed as a decimal number that ranges from 0 to 255. For example, the binary IP address above becomes 33.96.187.2.
Every host in a network has an IP address. For example, the computer where this website is stored has an IP address of 107.170.164.113. IP addresses are used to uniquely identify hosts over a network and allow information to be sent between them. You can think of an IP address as the address written over an envelope.
When a datagram travels over the Internet, it contains in its header the IP addresses of both the source and the destination. Routers parse the datagram header, read those addresses and redirect the datagram accordingly.
The IP address seen above is known as IP version 4, or IPv4 for brevity. Since an IPv4 address is a 32-bit binary number (4 octets, [texi]4\times8 = 32[texi]), the maximum amount of unique IP addresses is [texi]2^{32}[texi] — around four billions. Apparently a big number, but not enough for the modern, ever-expanding Internet and the devices that every day want to connect to it.
For this reason, IETF engineers introduced another format known as IP version 6 (IPv6), a 128-bit number where each 16-bit segment is separated by a colon (:). The segments are called hextets and are usually written as four hexadecimal digits. For example, 2001:0db8:0000:0000:0000:8a2e:0370:7334 and 1327:7e23:249e:6ee7:400e:e531:c62d:47b1 are both valid IPv6 addresses. An IPv6 address written in binary format would be too large to read.
Using the IPv6 format allows for [texi]2^{128}[texi] addresses, a number that is even difficult to imagine. The Internet infrastructure is slowly adopting the new IPv6 format, while it will still be possible to use existing IPv4 addresses for the foreseeable future due to backward compatibility.
Routers are responsible for assigning IP addresses to hosts that join their networks. When you connect your device to the Internet through your Internet Service Provider (ISP), one of the ISP routers assigns an IP address to your router, which can be seen as a host in the ISP network. Such IP address is visible from any part of the Internet and is called public address. At the same time, your router assigns another IP address to your device, visible only inside your local network. This IP address is called private address.
Imagine you live in France and want to send a letter to a friend in Italy through the physical mail service: while writing the address, you will add the string Italy to determine the country of destination. Such information will be used by the postal service to optimize the routing: there is no need to send your letter to Asia if it is addressed to Europe, after all. This will prevent your package from floating around the wrong offices or taking unnecessarily long routes, which would increase the delivery time.
The same logic applies to the Internet, which is seen by the Internet Protocol as a big hierarchical structure of networks and hosts. A network is like the country in a physical postal service, while the host is the street address. In computer's terms, the network is the portion of the Internet in which the device is located, while the host is the device itself within that network. This information is extremely useful to optimize how datagrams flow across Internet routers, as seen in the example above.
The network and the host information is contained in the IP address. More specifically, a portion of the address called network prefix marks the network, the remaining part for the host is known as host identifier. All hosts on a network have the same network prefix. The Classless Inter-Domain Routing (CIDR) notation is the modern way to specify which part of the IP address is used for the network prefix and which one is used for the host identifier.
The CIDR notation looks like this:
[IP address]/[mask]
Where [IP address] can be both IPv4 or IPv6 and [mask] — the network mask — tells the number of bits in the IP address reserved for the network, while the rest is for the host. The two numbers are separated by a slash ('/'). For example, an IPv4 address written as 33.96.187.2/24 means that the first 24 bits — the 33.96.187 part, usually written as 33.96.187.0 — represent the network prefix, while 2 is the host identifier. The same logic applies to IPv6.
An IP address written in CIDR notation also tells you how many hosts can exist in a specific network. In the example above 33.96.187.2/24, 8 bits are reserved for the host identifier, which means up to [texi]2^{8} = 256[texi] hosts in that network.
You usually don't see IP addresses written in the CIDR notation because you don't need it as an Internet user. However, the CIDR-ed version is always passed to routers: they unpack the IP address as specified by the network mask, grab the network information and route the datagrams to the right location. Operating systems too need to know this information to determine if a datagram should be sent to other hosts on the same network or to the outside world.
The concept of network mask seen above exists to allow the creation of subnetworks, a practice known as subnetting. Subnetting is the process of splitting up a network into two or more networks. This is done physically by installing new routers to mark the boundaries of the new subnetworks, and logically on the IP address by using some bits from the host part as a new network prefix, as seen in the picture below:
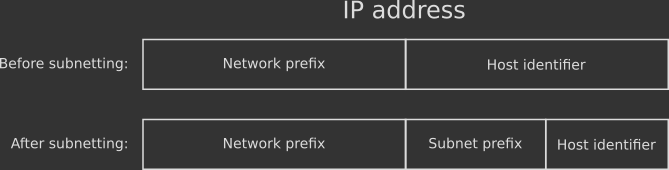
Subnetting is done by network administrators to create new, smaller networks out of existing ones. The operation brings several benefits. For example, subnetting improves the network performances: when a network is subnetted, different devices communicate with different routers rather than having all devices connected to a central router, which might become busy. Subnetting also increases security and reliability: subnetworks are isolated, so a problem in a specific subnetwork won't propagate to others.
Subnetting was also used back in the IPv4-only days to optimize the small number of addresses available, especially in enterprises networks. The huge amount of IP addresses available with IPv6 has fixed the problem for good.
The Internet Protocol is about the software side of the Internet, like any other protocol in the TCP/IP protocol stack: it is designed to be hardware independent and may be implemented on top of any physical technology. As a consequence, all the instructions and requirements outlined by the Internet Protocol are implemented into operating systems that run on routers and user devices.
Many other protocols use the Internet Protocol as a foundation: the most important one is TCP as I have mentioned multiple times throughout this article. In the next episode of this series I want to explore such protocol from a theoretical point of view. Then I will get my hands dirty with network programming, to put in practice what we have found so far. Stay tuned!
RFC791 — Internet Protocol specification
Cloudflare — What is a router?
Cloudflare — What is the Internet Protocol?
System Engineer @ YouTube — Routed vs Routing Protocols
Security.stackexchange — With IPv6 do we need to use NAT any more?
Wikipedia — IPv4 address exhaustion
Wikipedia — Classless Inter-Domain Routing
Wikipedia — Subnetwork
Wikipedia — IP address
Wikipedia — IP header
Wikipedia — IP routing
Wikipedia — Router (computing)
Wikipedia — Routing protocol
Wikipedia — Connectionless communication
Microsoft — Understand TCP/IP addressing and subnetting basics
Internet Society — Frequently Asked Questions (FAQ) on IPv6 adoption and IPv4 exhaustion
Cisco — Host and Subnet Quantities
Computer Networking Notes — IP address, Network address, and Host address Explained
Enterprise Networking Planet — Networking 101: Understanding Subnets and CIDR