
Join us on Facebook!
Join us on Facebook!
— Written by Triangles on April 27, 2021 • updated on May 06, 2021 • ID 89 —
The official rules that allow computers to communicate over the Internet.
Introduction to computer networks — A bird's-eye view on the art of resource sharing from one computer to another.
Understanding the Internet — “Is that thing still around?” — Homer Simpson
Introduction to IP: the Internet Protocol — From routing to IP addressing, a look at the protocol that gives life to the Internet.
Introduction to TCP: Transmission Control Protocol — One of the most important, high-level protocols in the Internet Protocol Suite.
Network programming for beginners: introduction to sockets — A theoretical look at one of the most popular programming tools for exchanging data over computer networks.
Making HTTP requests with sockets in Python — A practical introduction to network programming, from socket configuration to network buffers and HTTP connection modes.
Welcome to the third chapter of the Networking 101 series! In the previous episode I have investigated the nature of one of the most popular network of networks on planet Earth known as the Internet. In this one I want to get a little more technical and understand how the Internet works under the hood.
The Internet is a huge collection of different networks that talk to eachother and exchange information. The result is a complex machinery that requires specific rules in order to operate correctly: those rules are called protocols. The Internet has its own protocol known as the Internet Protocol Suite, often also called the TCP/IP protocol.
The Internet Protocol Suite is a collection of protocols — that's what the word suite stands for — that determines how the Internet should work. The TCP/IP alias comes from two of the most important protocols the Internet Protocol Suite contains: the Transmission Control Protocol (TCP) and the Internet Protocol (IP). From now on I will refer to it as the TCP/IP protocol stack for brevity.
Initially developed by the United States Department of Defense and now maintained by the Internet Engineering Task Force (IETF), the TCP/IP protocol stack defines how data should be handled, transmitted, routed, and received over the Internet. Anything that is connected to the Internet or operates with it must comply with the rules defined in the TCP/IP protocol stack. Two machines that want to communicate over the Internet must both implement the TCP/IP protocol stack in order to talk to eachother correctly.
For example, the web browser you are using to read this article implements the Hypertext Transfer Protocol (HTTP), one of the many protocols in the TCP/IP protocol stack and the foundation of the World Wide Web (WWW). The HTTP protocol determines how the text you are reading right now should be sent from the web server — the remote computer that stores the information — to your web browser, over the Internet. The protocol also describes how your browser should talk to the web server in order to initiate the data exchange.
Many other software parts must be TCP/IP compliant. For example, the operating system running on your device has to implement several protocols from the TCP/IP suite, in order to provide Internet capabilities to the entire system (web browser included!).
You won't find instructions on how to build networks, how signals should travel through cables and so on: the TCP/IP protocol stack is designed to be hardware independent and may be implemented on top of any physical technology. For example, some IETF engineers during the April Fool's day designed the IP over Avian Carriers (IPoAC): a proposal to carry Internet traffic by birds such as homing pigeons.
Cables and computers that make up the Internet infrastructure understand a very simple binary language made of zeroes and ones, and yet we want to be able to move rich data around such as web pages, emails, movies, video calls, … in a reliable, error-free and easy to establish way. This is a complex problem that must be broken down into smaller pieces to be solved efficiently. For this reason, the TCP/IP protocol stack has been organized into four layers.
Each layer contains protocols that describe how to route/transmit/receive data according to a different level of abstraction. The lower the layer, the closer you are to the hardware and the more detailed the instructions are; the higher the layer, the closer you are to the human and the more abstract the communication becomes. Let's take a bottom-up look:
Link layer — also known as the physical layer, it contains protocols that operate very close to the metal. Protocols in this layer see the network as a bunch of machines physically linked together that exchange bits of data;
Network layer — also known as the Internet layer, this is where the communication starts to get fancy. Protocols in this layer think in terms of source networks and destination networks and how to identify them;
Transport layer — here the communication becomes even more abstract. Protocols in this layer think in terms of processes that talk to eachother through specific channels;
Application layer — the most abstract layer, where protocols think in terms of user services that exchange application data over the network.
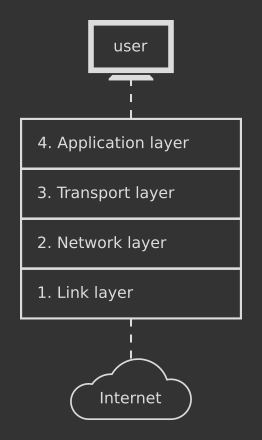
The idea behind the TCP/IP protocol stack is to use layers to abstract away the underlying complexity. Two applications that want to exchange data over the Internet will both use protocols in the layer #4, then they rely on protocols from the layers below for the actual transmission or reception. The following example will help to better understand how the whole thing works in practice.
Consider a web browser, based on the HTTP protocol (Application layer #4) that talks to a web server. When I type the website address in the address bar, the browser asks the web server for the web page the address points to. More specifically, the browser sends a piece of text to the web server containing the website address and other technical information. This is how the HTTP protocol defines the communication between a browser and a web server.
However, two machines over the Internet need more low-level work in order to talk to eachother: what does "sending a piece of text" actually mean from a computer's perspective? The HTTP protocol doesn't care about it: instead, it relies on services provided by the Transport layer (#3) below to establish a form of browser-web server connection, whatever that means.
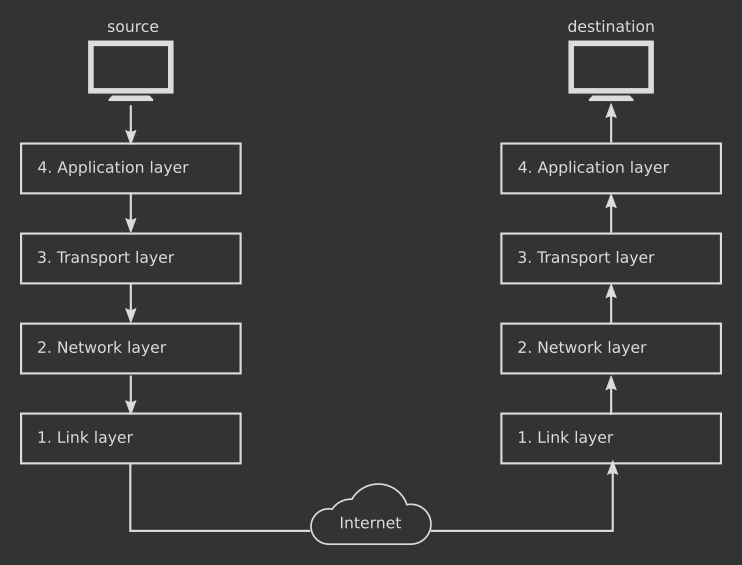
Protocols in layer #3 solve the upper layer's problems, yet they are still far away from true machine-to-machine interaction. For example: how is the address of the web server determined? Again, the software that implements the layer #3 protocols doesn't care about it: it relies on the Network layer (#2) below to handle such details. The pattern repeats until the Link layer (#1) is reached, where the data is physically transmitted over Internet cables.
At this point the message is flying across the Internet infrastructure. The information will eventually reach the web server: here the software that implements the HTTP protocol will rely on the underlying layers to transform the incoming data into something that the software can understand. Once done, the server can parse the data in the Application layer (#4) and react to the web browser's request. Notice how the data here goes through the layers in reverse order.
The layered approach described by the TCP/IP protocol stack offers another perspective on how information flows from one end to another: protocols on the same layer exchange data across two different machines as if they were directly connected through a virtual pipe. This is because the underlying mechanisms of communication are abstracted away by the lower layers (picture .3 below).
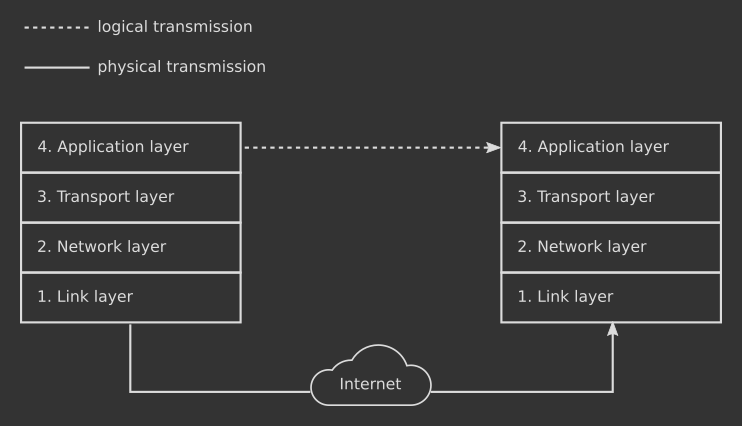
And also:
The table below lists few of the most important protocols contained in the TCP/IP protocol stack, along with the layer they belong to:
| Layer | Protocols |
|---|---|
| 1. Link | Address Resolution Protocol (ARP) — discovers machines over a network; Media Access Control (MAC) — establishes a channel between machines. |
| 2. Network | Internet Protocol (IP) — establishes a route between two points; Internet Control Message Protocol (ICMP) — sends operational information (e.g. success or failure) between two points. |
| 3. Transport | Transmission Control Protocol (TCP) — provides reliable and ordered stream of data between machines communicating via an IP route; User Datagram Protocol (UDP) — same as TCP, but less reliable and unordered; |
| 4. Application | Hypertext Transfer Protocol (HTTP) — the foundation of the World Wide Web; File Transfer Protocol (FTP) — transfers files between computers; Secure Shell (SSH) — enables two computers to securely share data over an unsecured network; Voice over Internet Protocol (VoIP) — allows phone calls over an Internet connection. |
The TCP/IP protocol stack wants the data to be split into chunks called packets or, more formally, protocol data units (PDU). In telecommunication, the method of transmitting data into packets is called packet switching. The benefit of this technique is that data can be routed to a destination through any number of transmission points, making the network more resistant to hardware failure.
Beyond actual data, protocols need to exchange information between the sender and the receiver in order to work correctly. For this reason, each packet is made of a header and a payload. The header contains instructions relevant to the protocol in use, the payload contains a portion of the message to be delivered. Programs that implement the TCP/IP protocol stack take care of filling the headers with the right information and splitting the data into packets.
Packets are generated in the Application layer (#4) during an outgoing transmission. As they slide down the stack, the protocols at each layer wrap those packets with their headers. The process is known as encapsulation and works like the Russian dolls where each doll contains another smaller doll inside of it. Data coming out the last layer contains all the headers added by the protocols above.
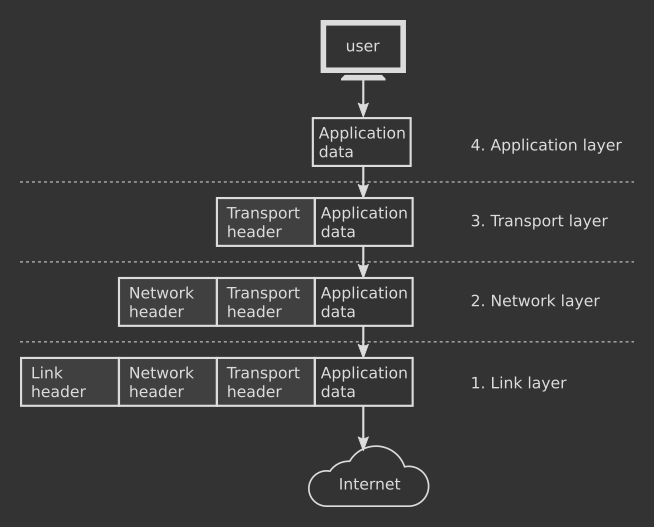
As soon as the data approaches the destination machine, the inverse process known as decapsulation begins. The Link layer (#1) receives the data from the network, reads the instructions written in the packet header in order to perform its own duties and peels the header off of the packet. The peeled data is then passed to the upper layer: the pattern repeats until the naked data reaches the Application layer (#4) on the receiver side. Here the information is identical to what has been sent by the sender and can be processed by the receiver's application.
This article wanted to be a kind of lightweight introduction to the TCP/IP protocol. In the next few ones I plan to investigate two of the most important components it is made of, namely the TCP and the IP protocols. Once the abstract exploration is done, I will get my hands dirty with something ever cooler known as network programming: writing programs that work over the Internet. See you on the next episode!
Computer Networks — A. Tanenbaum, D. Wetherall
Wikipedia — Internet Protocol Suite
Wikipedia — Encapsulation (networking)
Oracle — Data Encapsulation and the TCP/IP Protocol Stack
ITPRC — How Encapsulation Works Within the TCP/IP Model
whatismyipaddress — What is a TCP/IP Packet?