
Join us on Facebook!
Join us on Facebook!
— Written by Triangles on June 18, 2022 • updated on July 03, 2022 • ID 96 —
How not to get lost in a multilingual world.
สวัสดีครับ! — If you can read that — hello! in Thai, your computer can display characters outside the standard Latin set we are all familiar with. Today any modern operating system supports multiple languages and writing programs that ship that feature has become quite easy. In this article I want to collect some useful wisdom for making software that speaks more than one language.
Our journey starts with an introduction to the most important tool in multi-language support: the Unicode Standard — or Unicode in short. Born at the beginning of the 90s, Unicode is a specification that lists every character used by human languages on Earth and assigns each character a unique number. The result is an evolving document that you can browse online on the Unicode official website (the latest version is 14.0.0 as of this writing).
In essence, Unicode is a collection of tables, one for every language. Each table contains the list of characters that make up that language, plus the unique numbers assigned to them. For example, this is the table for Basic Latin characters, the same ones you find on this web page. This is for Arabic; this is for Egyptian Hieroglyphs; this is for mathematical operators an this is for emoticons. Yes, Unicode covers also crazy stuff.
Unicode lists characters, and each character is mapped to a unique number called code point. For example, in the picture below you can see the Unicode character a with its own code point:

a maps to Unicode U+0061 code point.A code point is a hexadecimal number that ranges from 0 through 10FFFF (1,114,111 in decimal format). They are denoted as U+[number], for example U+0061 in the picture above. The current Unicode version lists 144,697 characters, roughly 13% of the available space.
Some characters may have their own code point, but may also be generated by joining multiple code points together. For example, the character é (Latin Small Letter E with Acute) is both the U+00E9 code point and the combination of e (Latin Small Letter E) at code point U+0065 with the Combining Acute Accent at code point U+0301, as you can see in the picture below:
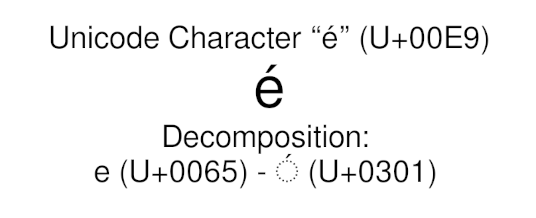
é maps to Unicode U+00E9 code point but can also be composed by joining smaller units.This is one of the Unicode features that may hurt you when working with text in a programming language, as we will see in few paragraphs.
In computers, everything — music, movies, programs, text, ... — is made of binary data: a long stream of 0s and 1s. The problem: say you have a chunk of binary data like 0110100001101001 and you know it is a text string: how do you interpret it or display it to users correctly?
A computer needs a character encoding in order to solve that problem. A character encoding is a way of mapping those 0s and 1s to something meaningful, so that the computer can interpret it and possibly display it in a way humans understand.
Unicode has its own character encoding called Unicode Transformation Format (UTF), which maps blocks of 0s and 1s to Unicode code points. If your operating system supports UTF, your computer can process and display any character available in the Unicode collection. For example, the text you are reading on this website is UTF-encoded. If you can read it, you are using a UTF-empowered operating system.
The UTF encoding comes in three variants: UTF-8, UTF-16 and UTF-32, where the trailing number corresponds to the minimum number of bits used for the encoding. UTF-32 is the most straightforward one: it always uses 32 bits (4 bytes) to store any Unicode character, even when not necessary because the Unicode point is small. UTF-16 and UTF-8 employ clever tricks to optimize the required bytes instead. For this reason they are known as variable-width encodings.
The table below shows how the three different UTF variants encode U+0065 (Latin Small Letter E):
U+0065 - Latin Small Letter E
UTF-8: 65
UTF-16: 00 65
UTF-32: 00 00 00 65
Currently, UTF-8 is the most popular one. It is also the dominant encoding for the World Wide Web and Internet technologies. UTF-8 is probably what you want if your programs need to support Unicode.
One of the key roles of an operating system is to get keystrokes from the user and show text on screen: for this reason it must know how to deal with character encoding. All modern operating systems support UTF, as well as many other encodings that predate it.
Specifically, Unix-based operating systems such as Linux and macOS use UTF-8. Windows uses UTF-16 internally, but modern versions added support for apps working with UTF-8.
The character encoding to use is stored in the operating system's locale: a collection of user preferences such as the language to use, how to format numbers, dates, currency symbols and so on. Every operating system has tools to query the character encoding in the current locale (and the locale itself too, of course). For example, on Linux I can do it with the locale charmap command, which prints UTF-8 as expected. You can change the operating system's locale, and so the character encoding, via the configuration tools.
Operating systems need fonts to display characters. A font is a file containing letters, symbols and other graphical elements that the operating system renders on screen. Those symbols are called glyphs. Some fonts are Unicode-compliant: they map glyphs to Unicode code points. You need to install a Unicode font if you want to display Unicode characters.
For example, the Arial Unicode MS is a proprietary Unicode font that contains Latin glyphs as well as many other eastern languages, which are not available in the standard Arial. The GNU Unifont is a free Unicode font available on Linux and other open-source operating systems.
Common font formats cannot contain more than 65,536 glyphs (16-bit), so no single Unicode font can include all the characters defined in the Unicode standard. Font developers overcome such limitation by shipping separate auxiliary fonts intended specifically for particular languages or symbols.
If a font doesn't contain the glyph for the code point used in the document, you will typically see a question mark, a small box or some other placeholder.
Text files are saved to disk with a certain encoding. All modern editors support UTF: I'm writing this article in Visual Studio Code and I can save it either in UTF-8 or UTF-16, where UTF-8 is the default (not sure why UTF-32 is not available, though).
Normally a text file doesn't contain information on the encoding in use: text editors use internal heuristics to determine it. Some Unicode text files may contain a kind of signature at the beginning known as byte-order mark (BOM). This is a special, invisible Unicode character Zero Width No-Break Space (U+FEFF) used to identify UTF-encoded files, a trick proposed by Microsoft back in the early Unicode days. Today no text editor adds it anymore, especially on Unix-like operating systems.
It's a good idea to save also source code files in UTF, so that you can put Unicode characters in them. Modern compilers and interpreters know how to deal with UTF-encoded source files with no problem. More on that in few paragraphs.
A string of text, in binary form, may reach a program from several sources: a series of user keystrokes, a file read from disk or the Internet. A program that just stores that text, or redirects it somewhere else — for example it prints it to screen, doesn't need to be aware of the character encoding in use. This is because interpreting the string as a bunch of bytes is enough for being carried around or stored in memory.
On the other hand, programs that perform text manipulation such as text editors must know if the string is UTF-encoded or not. For example UTF-8 encoding may use more than one byte for a single character, so the program needs to understand the boundary of each character, in bytes, in order to handle it correctly.
Consider this:
ɣ-rays
If encoded in UTF-8, the string above maps to the following bytes (written in hexadecimal format):
ɣ - r a y s
| | | | | |
0xC9 0xA3 0x2D 0x72 0x61 0x79 0x73
Now, imagine you want to count the number of letters in the string above. You'll get the wrong answer, 7, if your program just counts bytes without taking the UTF-8 rules into account. The same problem is relevant to any other text transformation such as cutting, trimming, flipping the case, sorting, filtering, getting the character at position n and so on.
Comparing Unicode strings is tricky as well. Remember how the same character can be represented by different sequences of code points? The following equality might be false:
perché == perché
if the é character in the left string is represented as a single code point U+00E9 (Latin Small Letter E with Acute) and the è character in the right string is represented as U+0065 + U+0301 (Latin Small Letter E + Combining Acute Accent).
Many high-level programming languages speak Unicode. For example, in Python 3 text is stored in UTF-8, while JavaScript uses UTF-16. In Rust, a low-level language, strings are UTF-8 encoded. Those languages understand strings at the character level, which makes string comparison and manipulation easy.
Consider the following Python 3 example:
text = "ɣ-rays"
print(text[0])
It will print the first character, ɣ, as expected. Of course this is valid for every other language that support UTF encoding natively.
UTF-aware languages also provide tools for the so-called Unicode normalization (or canonicalization): the process of converting text to a form in which all the Unicode ambiguities seen before ("perché" == "perché") are not present. Normalization is a mandatory step for correct string comparison and should be done as soon as possible if your program accepts input from users.
Some programming languages understand strings just at the byte level, which makes Unicode string comparison and manipulation very hard to do correctly. In this case it is better to rely on external libraries if you really need to perform heavy text work. For example, International Components for Unicode (ICU) is a popular library that provide full Unicode support to C, C++ and Java.
Languages such as C and C++ require special care even if you are just storing text in memory with no manipulation. For example:
char gamma = 'ɣ';
This code will not compile in C and C++. The ɣ character is made of two bytes in UTF-8 encoding (U+0194) but the char type takes a memory size of only one byte. The two languages tried to overcome this by adding the wchar_t type, known as wide character: a type large enough to contain any Unicode character. Unfortunately the size of wchar_t is compiler-specific and can be as small as 8 bits. Consequently, programs that need to be portable across any C or C++ compiler should not use wchar_t for storing Unicode text.
C and C++ recently added more Unicode-friendly types such as char8_t (for UTF-8), char16_t (for UTF-16) and char32_t (for UTF-32). They will help you storing Unicode string correctly, but all the text manipulations previously discussed are still left to you.
Most programming languages allow you to put Unicode characters right into string literals: that's what I did through all this article. For example, this is valid Python 3 code:
string = "Ναι" # "Yes" in Greek
print(string)
This is because compilers and interpreters are able to read UTF-encoded source files, assuming you correctly saved them with a UTF encoding. Some languages also allow you to put Unicode characters in function and variable names. It might hurt readability — or maybe not? Consider the following usage of mathematical symbols in Java:
float Δ = 32.0;
float π = 3.1415;
float result = Δ * π;
Many programming languages also support escape sequences, used to map a sequence of hexadecimal numbers the corresponding Unicode code point. A JavaScript example:
const string = "\xE2\x88\x83y \xE2\x88\x80x" // ∃y ∀x — written with the \x[NN] escape sequence
C, C++, Python and others have also Unicode-specific escape sequences that look like \u[...] or \U[...]. Anyway, using escape sequences in string literals kills readability. Sometimes this is the only way to fit Unicode text right into the source code though, if your compiler/interpreter doesn't understand it.
Unicode official webside
Python docs — Unicode HOWTO
Joel On Software — The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets
UTF-8 Everywhere
Artem Golubin — How Python saves memory when storing strings
Wikipedia — UTF-8
Wikipedia — Unicode
Wikipedia — Unicode font
Markus Kuhn — UTF-8 and Unicode FAQ for Unix/Linux
Microsoft docs — Working with Strings
Apache C++ Standard Library User's Guide — Differences between the C Locale and the C++ Locales
libc manual — How Programs Set the Locale